
NVIDIA Quantum-X800: Next Generation Infiniband 800Gbit/s Network Topology
Infiniband Design Tradeoffs and maximizing perf/TCO with correct rail group size

At GTC 2024, Jensen announced Infiniband Quantum-X800 which allows 800Gbit/s of bandwidth using 224G serdes. Boasting an impressive higher radix of 144 ports compared to 64 ports in last generation’s Quantum-2 switch. This article dive into the balance between performance and cost implications involved in picking rail group size to match your current and future workloads. Should you have a rail group size of 288 or 576 or higher?
Disclaimer: only publicly available information will be used and analyzed within this blog post.

Rail Optimized Network Topology
In H100 & B100 400Gbit/s Infiniband Rail Optimized design, each rail group of 32 servers has 8 rails. This is so each gpu within it’s rail can talk to each other without going to the top level switch. This was explained in the analysis of the 5 different network fabrics post and we will recap again.


The reason why this is extremely important for modern LLM training is that through clever communications algorithms and taking advantage of the intar-node NVLink network, you can achieve a 2x throughput in all2all network performance for large messages and 2x reduction in latency for small messages. This feature is called PXN (enabled with NCCL_CROSS_NIC=1) and enables for a GPU to RDMA through the NVLink fabric to a different rail such that it can directly talk to another node’s GPU with only going through a leaf switch instead of doing 2 hops through the spine. The reason why this is much faster is because the NVLink is 9x faster than Infiniband and has tighter latency requirements.

All2All collective performance is increasingly critical in the age of mixture of experts where expert parallelism requires this network bandwidth heavy collective. Note that rail-optimized networks doesn’t have any effect on all-reduce algorithms. Crouse & Mixtral was able to benchmark real world training throughout on rail-optimized networks and found that at the O(240 H100) scale, it was about 14.2% higher throughput. It is expected that this rail optimization improvement scale to the O(tens of thousands) as long as your expert parallelism is done within a rail group.

EOS Cluster Infiniband Network Topology
According to the NVIDIA Superpod Reference Architecture, each rail group has 32 nodes (256 gpus) and a rail group of 32 nodes.
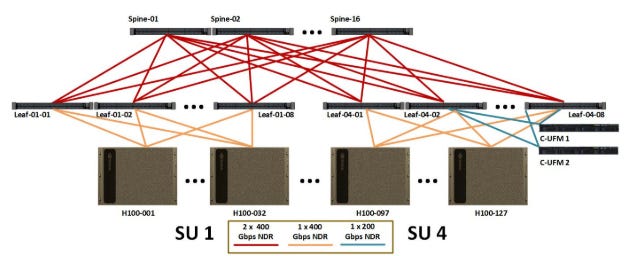
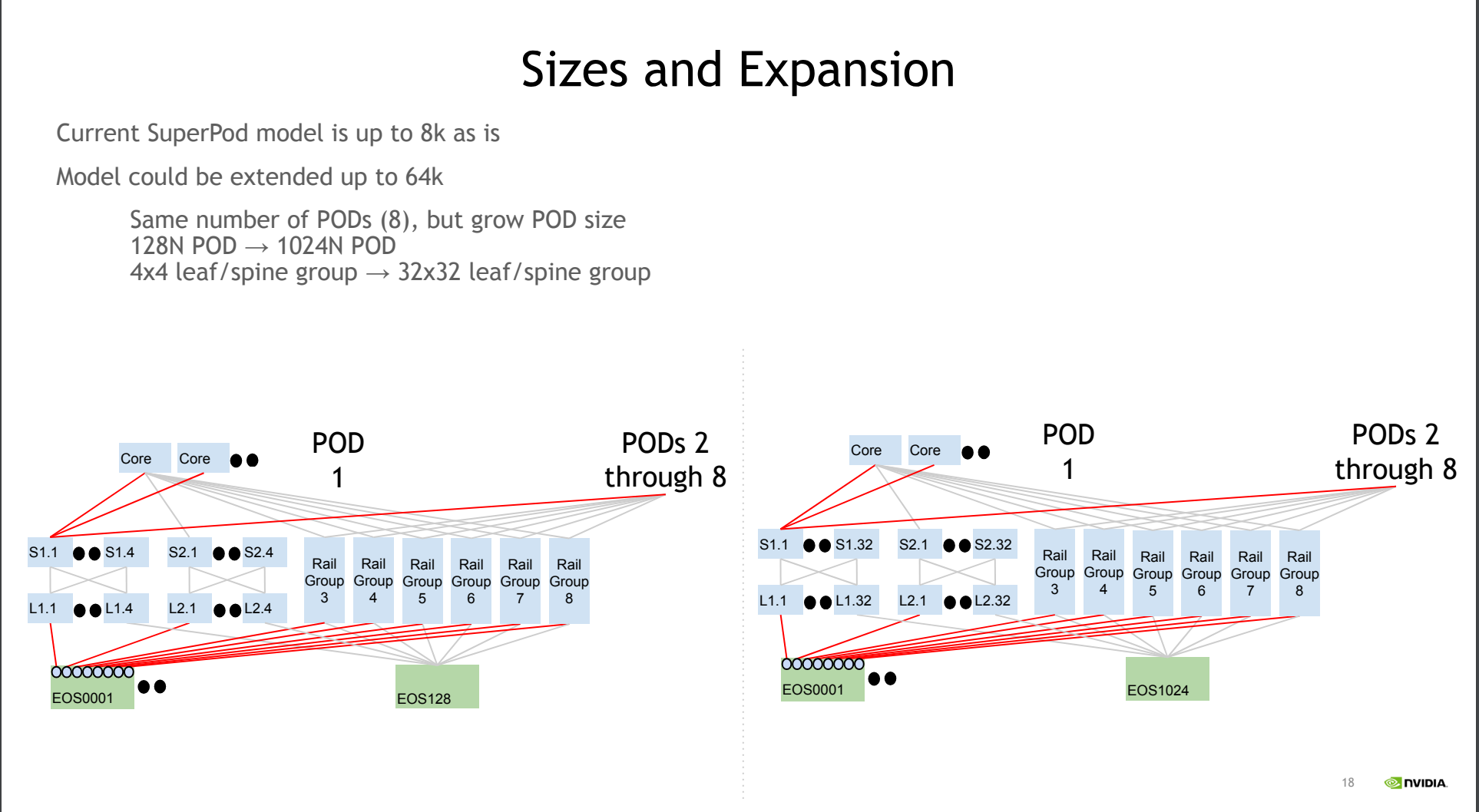
With NVIDIA’s EOS cluster, they have a rail group of size 128 nodes (1024 GPUs) by building a “virtual modular switch” for each rail. As you can see in the left side of the diagram below, each rail has 8 switches interconnected together to form a “vritual modular switch” for that rail. All GPUs at each index is able to talk to another GPUs at the same index without going through the top level switch. By using a rail group of size 128 nodes, they are able to expand to cluster to 8k GPUs on NDR Quantum-2 switches. In order to expand to the cluster up to 64k H100s, they need to use a rail group size of 1024 nodes (8096 H100s). That means each “virtual modular switch” for the rail will use 64 switches instead. Within the pod of 8096 GPUs, all GPUs at each index is able to talk to another GPUs at the same index without going through the top level switch.
Quantum-X800 Network Design
With the next-gen Quantum-X800 IB switch, each switch supports a radix of 144 800Gbit/s ports compared to Quantum-2 IB switch, which only supports a radix of 64 400Gbit/s ports. With a higher radix, you can connect more nodes together with less switches. Since each GB200 has a 4 GPUs per node, they have moved from doing 8-rail to just 4-rail.
In the draft example fabric design for 1152 GPUs presented at GTC 2024, they choose a rail group of 576 GPUs by forming a “virtual modular switch” using 4 Quantum-X800 switches per rail and a 3 tier network topology. This is a surprising design especially at the 1152 GPUs level where you can just do a 2-tier network topology with a rail group of 288 GPUs. You can do a rail group of 288 GPUs by using 4 leafs switches per rail group (576 800Gbit/s port for 4 switches, 288 for downlink to GPUs, 288 for uplink to top level switches). By using a rail group of 576 GPUs, they are able to have a bigger region for expert parallelism, which increased performance for all2all collectives by using PXN as explained above.
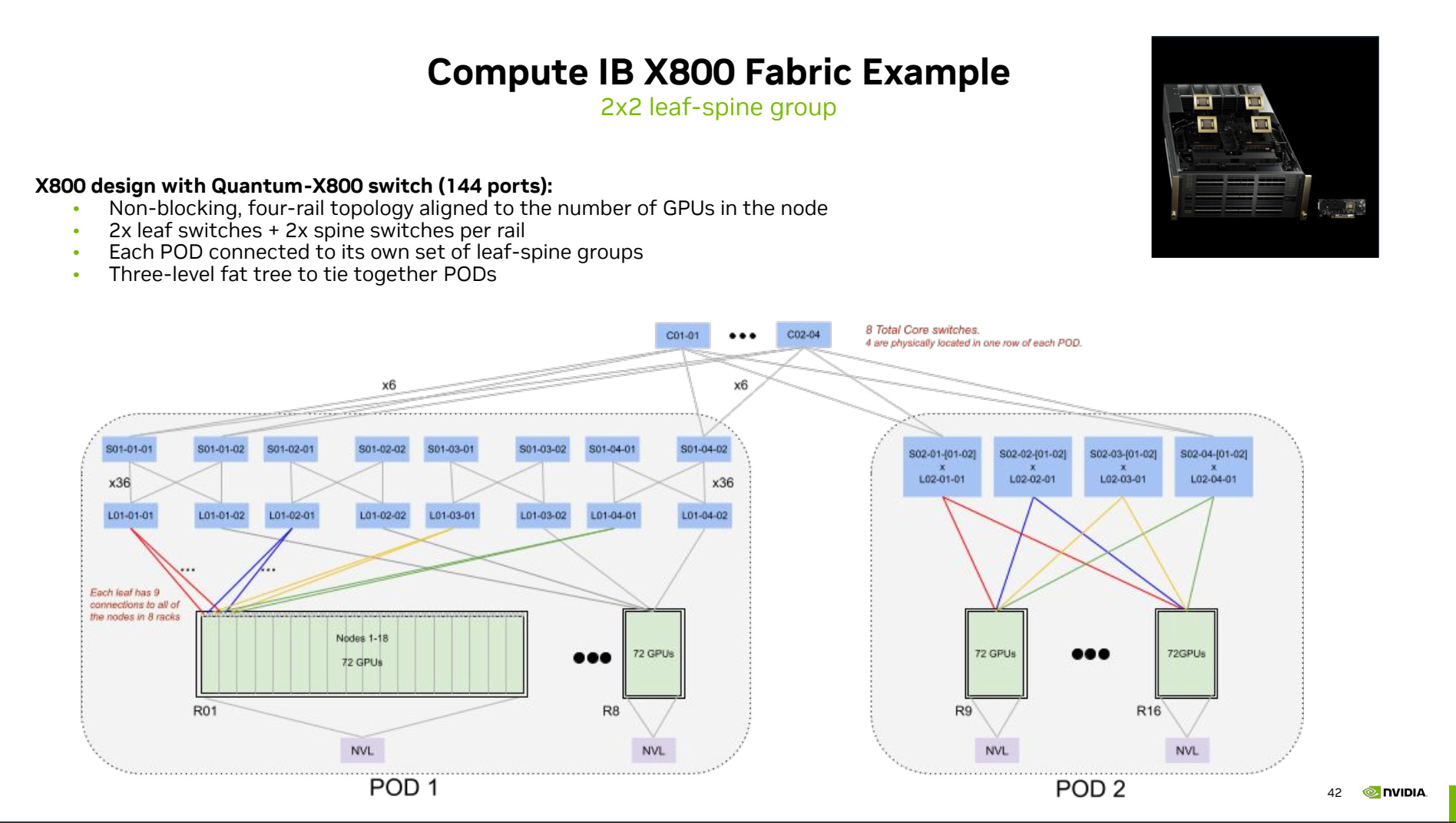
By picking a rail group size of 576 Blackwell GPUs with a 3 tier network instead of rail group of size 288 GPUs with a 2 tier network. This increases the quantity (think cost) of IB switches by 50% and number of twin port transceivers by 50%.

It will be seen if major customers opt for the more expensive rail group size of 576 instead of 288. If they are expecting that their model’s expert parallelism region to fit within 288 Blackwells (55 TeraBytes of GPU memory), then they will opt for that. If they expect scaling laws to continue to be exponential then it could be possible that they opt for a rail group size of 576 Blackwells (110 TeraBytes of GPU memory).