
H100/B100: Analyze of 5 Different Network Fabrics Types. Debate Between Infiniband and Ethernet
Analysis of Infiniband/RoCE Compute Fabric, In-band Management Fabric, Out of Band Management Fabric, Storage Fabric

Most H100/B100 analyst only debate about the pros and cons about Infiniband Vs RoCE Ethernet for the GPU compute fabric, but the GPU compute fabric is only 1 of 5 networks found on an typical DGX/H100 H100 superpod cluster. In this analyst, we will deep dive into the each one of the network and their purpose:
Infiniband/RoCE Ethernet Compute Fabric
In-Band Management Fabric
Out of Band BMC Management Fabric
Storage Fabric
NVLink Scale-Up Fabric
Disclaimer: only publicly available information will be used and analyzed within this blog post
Infiniband/RoCE Ethernet Compute Fabric
In H100/B100 cluster design, each GPU is directly connected to a 400Gbit/s network. With 8 GPUs, that means each HGX server has a 3.2Gbit/s (8x400Gbit/s) connection to the compute fabric. This network usually takes up 10-20% of the total capex of a cluster buildout.

Each GPU is directly talk to a NIC through a PCIe switch such that it doesn’t need to go through the CPU or through the PCIe root complex. This feature is called “GPUDirect RDMA” and increases realized bandwidth by quick a lot. Read out post on Benchmarking Infiniband and NVLink to learn more about it.

This fabric is designed to be 8-rail optimized in both H100 and B100, which means within a rail group of 32 HGX servers, a GPU in a rail can talk to another GPU on the same rail through one 1 hop through a leaf switch.

The reason why this is extremely important for modern LLM training is that through clever communications algorithms and taking advantage of the intar-node NVLink network, you can achieve a 2x throughput in all2all network performance for large messages and 2x reduction in latency for small messages. This feature is called PXN (enabled with NCCL_CROSS_NIC=1) and enables for a GPU to RDMA through the NVLink fabric to a different rail such that it can directly talk to another node’s GPU with only going through a leaf switch instead of doing 2 hops through the spine. The reason why this is much faster is because the NVLink is 9x faster than Infiniband and has tighter latency requirements.

All2All collective performance is increasingly critical in the age of mixture of experts where expert parallelism requires this network bandwidth heavy collective. Note that rail-optimized networks doesn’t have any effect on all-reduce algorithms. Crouse & Mixtral was able to benchmark real world training throughout on rail-optimized networks and found that at the O(240 H100) scale, it was about 14.2% higher throughput. It is expected that this rail optimization improvement scale to the O(tens of thousands) scale if you design your parallelization correctly to account of each rail group being only 32 HGX nodes.

It is critical that to design your network to be non-blocking which means for every switches’ uplink, there is the same number of downlink too. This will achieve a ratio of 1:1 blocking factor. At the 256-2048 B100 scale, only a 2 tier rail-optimized fat tree is needed. But once you are a above the 2048 endpoint scale, you need to move onto a 3 tier folded clos network topology or use dragonfly+. 3 tier folded clos is generally more flexible than dragonfly+ as dragonfly+ requires adaptive routing and congestion control as the shortest path may no longer be the fastest way to talk between GPUs.

Infiniband or RoCE Ethernet?
No doubt that infiniband is hella expensive and companies such as Meta is experimenting with RoCE Ethernet due to cost reasons. They have built two 24k h100 cluster, one with NDR 400G Infiniband and another with 400G RoCE Ethernet with Arista 7800 switches. Broadcom, Arista and Meta and claimed that the RoCE Ethernet cluster performs similar to their Infiniband cluster for LLM training after the appropriate network tuning. AWS EFA also uses 8x400G RoCE Ethernet with mixed performance (ask anybody that uses EFA if they like it) while GCP is a slower 8x200G custom built solution. GCP has built a custom called “GPUDirect-TCPX” such that the H100s can talk directly to an networking NIC through a PCIe switch. There are also the NVIDIA Spectrum-X series of RoCE Ethernet switches and Broadcom Tomahawk5 series. Broadcom Tomahawk5 supports 2x higher radix at 128 400Gbit ports per switch compared to NVIDIA Infiniband’s Quantum-2 switch which only provides 64 400Gbit ports. This translates directly to a 2x less switches (think 2x less cost for networking switches).
There is 2 unfortunate downside of choosing RoCE Ethernet over Infiniband. The first is a non-technical reason and it is that NVIDIA will not be happy and will not give you allocation for their latest and greatest GPUs if you do not buy Infiniband and pay the Infiniband premium. The next is that RoCE Ethernet does not support SHARP in network reductions. In theory SHARP doubles your all-reduce and reduce-scatter performance by allowing for reducing and aggregation within the the Quantum-2 switch. This requires the algorithm complexity from 2(n-1)/n writes and reads to just n+1 write and reads.

In-Band Management Fabric
The in-band management fabric is used for internet connection, data movements, SLURM, Kubernetes, downloading from package repos such as pypi, docker repo, gcr.io, etc. This is almost always an Ethernet fabric and can be either 2x100G or 2x200G with Dual Port ConnectX-7 or ConnectX-6 or Bluefield3s. The reason why it is 2x is that this is a crtical network and requires redundancy such that each node is independently connected to 2 different leaf switches. These 2 redundant network paths are bonded together so that if 1 of them goes down, there are be uninterrupted fallover.
Companies either choose the NVIDIA Spectrum3 Ethernet or NVIDIA Spectrum4 Ethernet series switches or just use any generic off the shelve networking gear as performance is not critical for this networking fabric.

Out of Band BMC Management Fabric
The out of band management fabric connects to the Base Management Controller (BMC) of each device in the whole cluster such as Compute fabrics, other Switches, management CPU nodes, UFM servers, Power Delivery Units (PDUs), etc.
The base management controller is used to change BIOS settings, monitor and set the node health such as fan speed, voltage levels, temperatures, PSUs etc. You usually interact with the BMC through IPMI or Redfish API or through the BMC web portal.

Out of band management network is usually extremely slow speeds at 1Gbit/s bandwidth as it is only needed for sending commands and management and not performance critical. Thus out of band management network costs usually makes up less than 0.5% of the whole capex of a cluster build out. You can use NVIDIA SN2000 series 1Gbit Ethernet series switches or any generic out of the shelve ethernet switch for this.
Storage Fabric
When storage performance is critical and you want to keep your sanity. This is so your GPUs have a direct path to the storage through GPUDirect Storage and when storage cluster rebuilds don’t eat up all your bandwidth. Parallel Filesystem vendors such as Weka and Vast are the main recommended vendor for high performance storage and when a rebuild is triggered (from a storage appliance going down), it eats up a ton of bandwidth and typically takes a couple of hours at the Petabyte scale. When there isn’t a dedicated storage fabric, you can entire have your storage traffic go through the in-band management network or even worse, on the compute fabric. When Weka rebuilds are triggered and your storage shared the same fabric as your compute fabric, your collective communication as all-reduce are noticeably slower. I usually take a lunch break when they happens XD.
Your storage fabric between your HGX compute node’s uplinks and your downlinks to your storage fabric is usually blocking. The storage fabric is usually highly dependent on each customer’s individual workload although NVIDIA recommends each node having a 2x200G Infiniband network and a blocking ratio of 4:3. Note that you can use Ethernet too for your storage fabric and have a higher blocking ratio and lower network bandwidth and the NVIDIA recommended design is usually overkill and designed for the worse case situation. Vertically integrated customer usually profile their workloads and estimate their future workloads to design their storage network to have the highest performance/TCO for these workloads. Furthermore, note that if you host shared home directories, they your latency and IOPS for this network would need to be extremely high in order to have good interactivity. If you don’t then your users type commands like “ls” or “pwd” and it will be lag.

NVLink Scale-Up Fabric
Nvlink is Nvidia’s proprietary network for scale-up computing between GPUs. Nvlink can either directly connect GPUs in a hypecube fashion like HGX P100 or uses a switching topology in HGX A100 and HGX H100. H100 Nvlink4 is ~9 times faster than Infiniband.
Most customers only opt for the intra-node NVLink configuration for H100 and provides 900Gbyte/s between all 8 H100s within a node.

With DGX H100 NVL256, you were able to connect 256 H100s (32 HGX nodes) together within a single Nvlink domain. But unfortunately, due the crazy price of requiring 18 fiber connections per node and requiring 18 external NVSwitches, there were low interesting amongst major customers. Thus DGX H100 NVL256 was internal only due to cost issues. You can read more about why this happen in this blog post.

With Blackwell NVL72, You can have 1800GByte/s bidirectional bandwidth between all 72 GB200s. this means it is ~18 times higher than the the 400Gbit/s Infiniband scale out fabric. This NVLink fabric is usually the most expensive as it provides the highest bandwidth and allows for higher tensor parallelism and faster FSDP/ZeRO3 parallelism.
The anticipated launch of the GB200 NVL72 is different. It is believed that NVIDIA has learned from the H100 NVL256's failure, addressing cost concerns by adopting copper interconnects instead of relying solely on fiber optics. NVIDIA calls this copper interconnect “NVLink Spine”. This shift in design is expected to reduce the cost of goods (COG), suggesting that GB200 NVL72 could be on a successful path where its predecessor faltered.
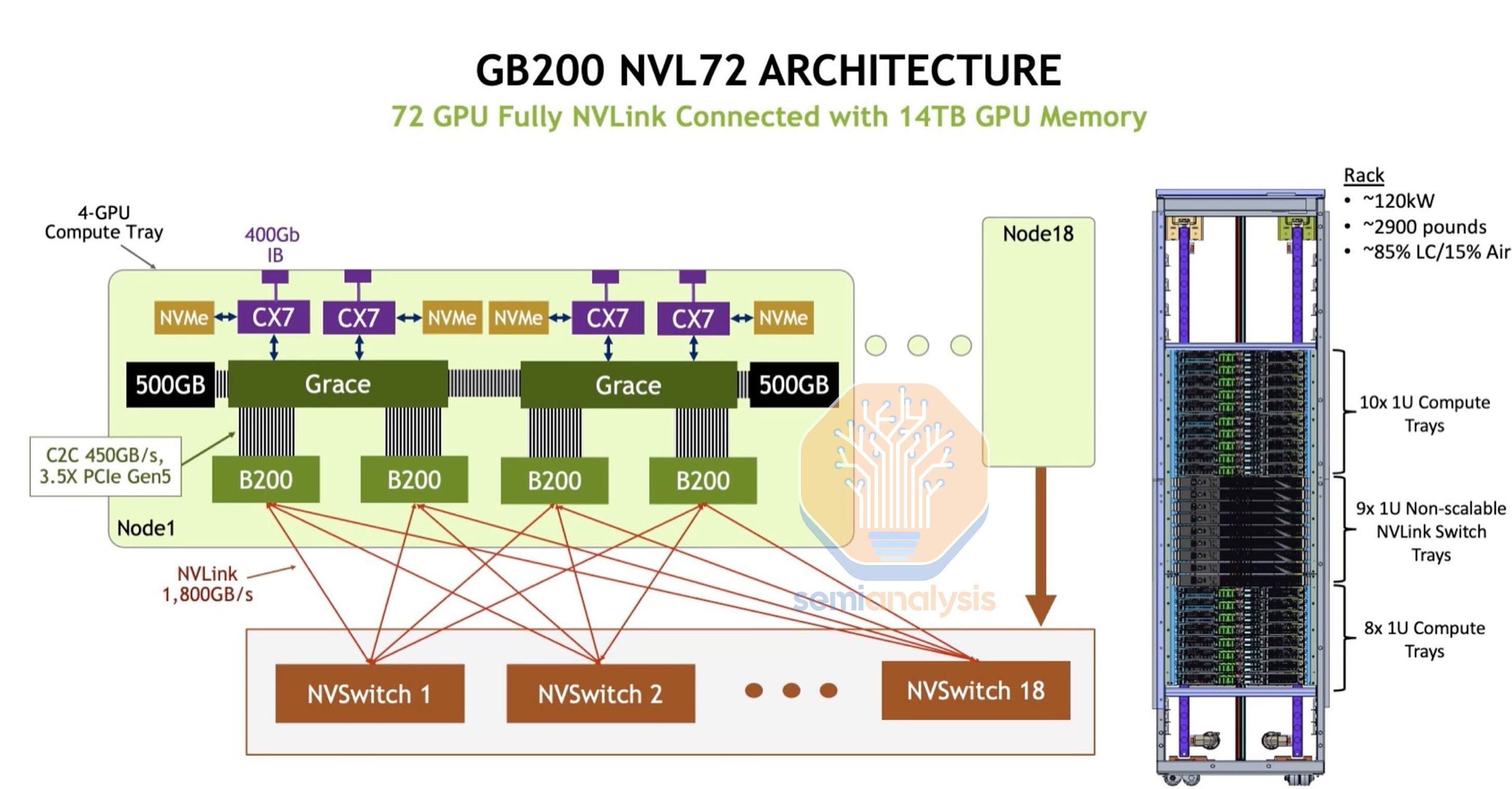
In conclusion, the intricate network architecture of H100/B100 superpod clusters, with its different fabrics including Infiniband/RoCE Ethernet Compute Fabric, In-Band Management Fabric, Out of Band BMC Management Fabric, Storage Fabric, and NVLink Scale-Up Fabric, represents a sophisticated ecosystem designed to optimize various aspects of data center operations. Each fabric is tailored to meet specific operational needs from high-speed compute and storage operations to management and scalability. Understanding the distinctions and functionalities of these networks is essential for maximizing efficiency and performance in GPU-accelerated computing environments.